Accountable Textual-Visual Chat Learns to Reject Human Instructions in Image Re-creation
Abstract
The recent success of ChatGPT and GPT-4 has drawn widespread attention to multimodal dialogue systems. However, there is a lack of datasets in the academic community that can effectively evaluate the multimodal generation capabilities of Visual Language Models (VLMs) in textual-visual chat tasks. In this paper, we address this gap by introducing two novel multimodal datasets: the synthetic CLEVR-ATVC dataset (620K) and the manually pictured Fruit-ATVC dataset (50K). These datasets incorporate both visual and text-based inputs and outputs. Furthermore, to facilitate the accountability of multimodal systems in rejecting human requests, similar to language-based ChatGPT conversations, we introduce specific rules as supervisory signals within the datasets. This allows the trained VLM to provide a yes or no answer after engaging in visual and textual reasoning, accompanied by a language explanation to clarify the reasons behind the inability to execute the given human instruction. Our proposed method involves a two-stage training procedure, which includes training the image auto-encoder and the auto-regressive transformer from scratch. The first stage employs a discrete variational autoencoder (dVAE) to compress each image into concise tokens, which are then combined with text tokens into a single data stream. This stream is subsequently fed into the decoder-based transformer to generate visual re-creations and textual feedback in the second stage. We conduct comprehensive analyses of experimental results, focusing on re-created image quality, answer accuracy, and the model's behavior when faced with uncertainty and imperfect user queries. Through our explorations and findings, we aim to contribute valuable insights into the accountability of textual-visual generative models.
Framework
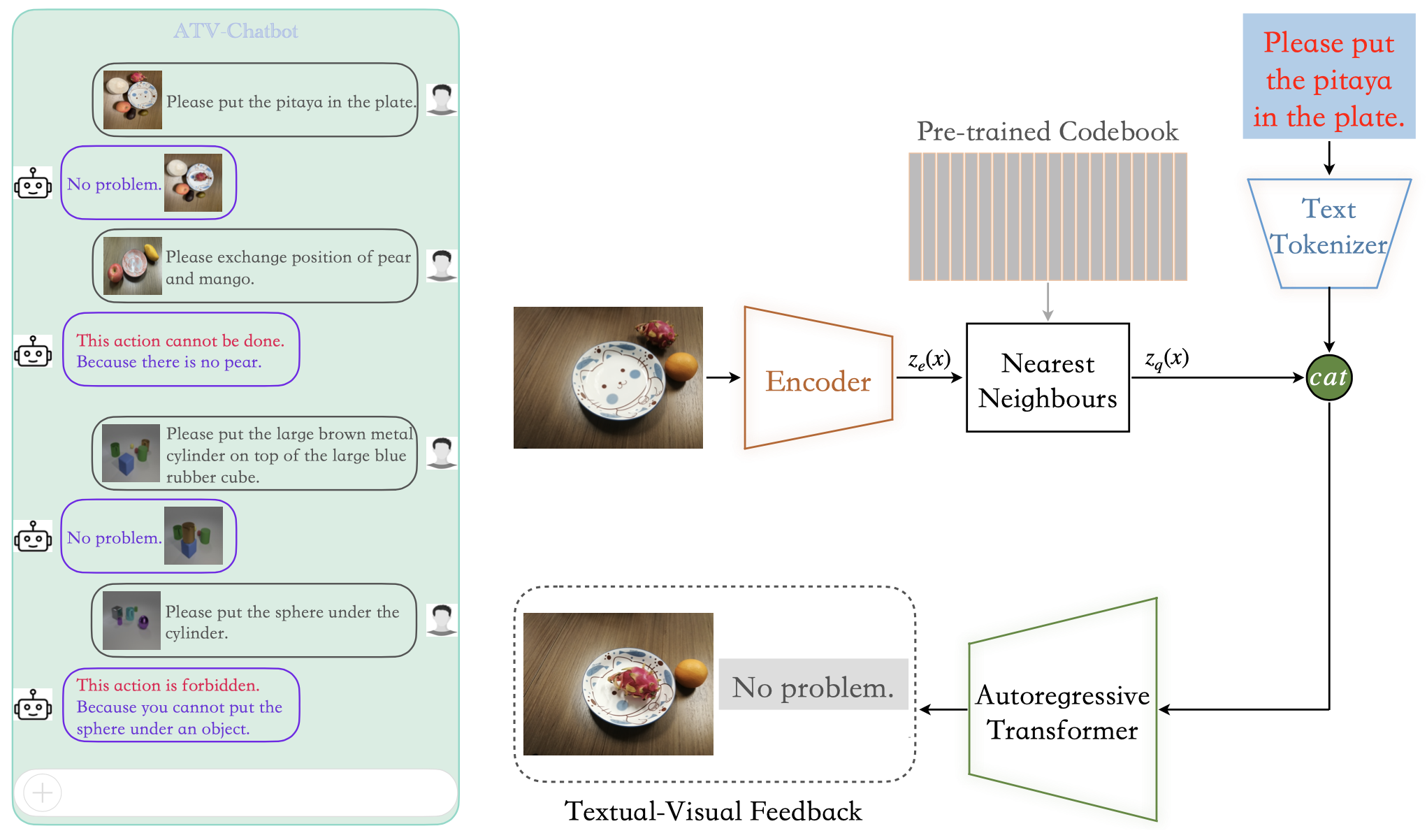
The left figure shows that a multimodal generative model can simultaneously recreate visual input and give textual feedback when faced with human instructions, especially it can reject some commands. The right figure illustrates the overall framework of our method. The model is required to generate a re-created image (M) and a textual feedback (A) conditioned on the visual input (V) and text-based user query (T), and the language-based explanation is also given for those instructions that cannot be executed and the prohibited instructions.
Experiments
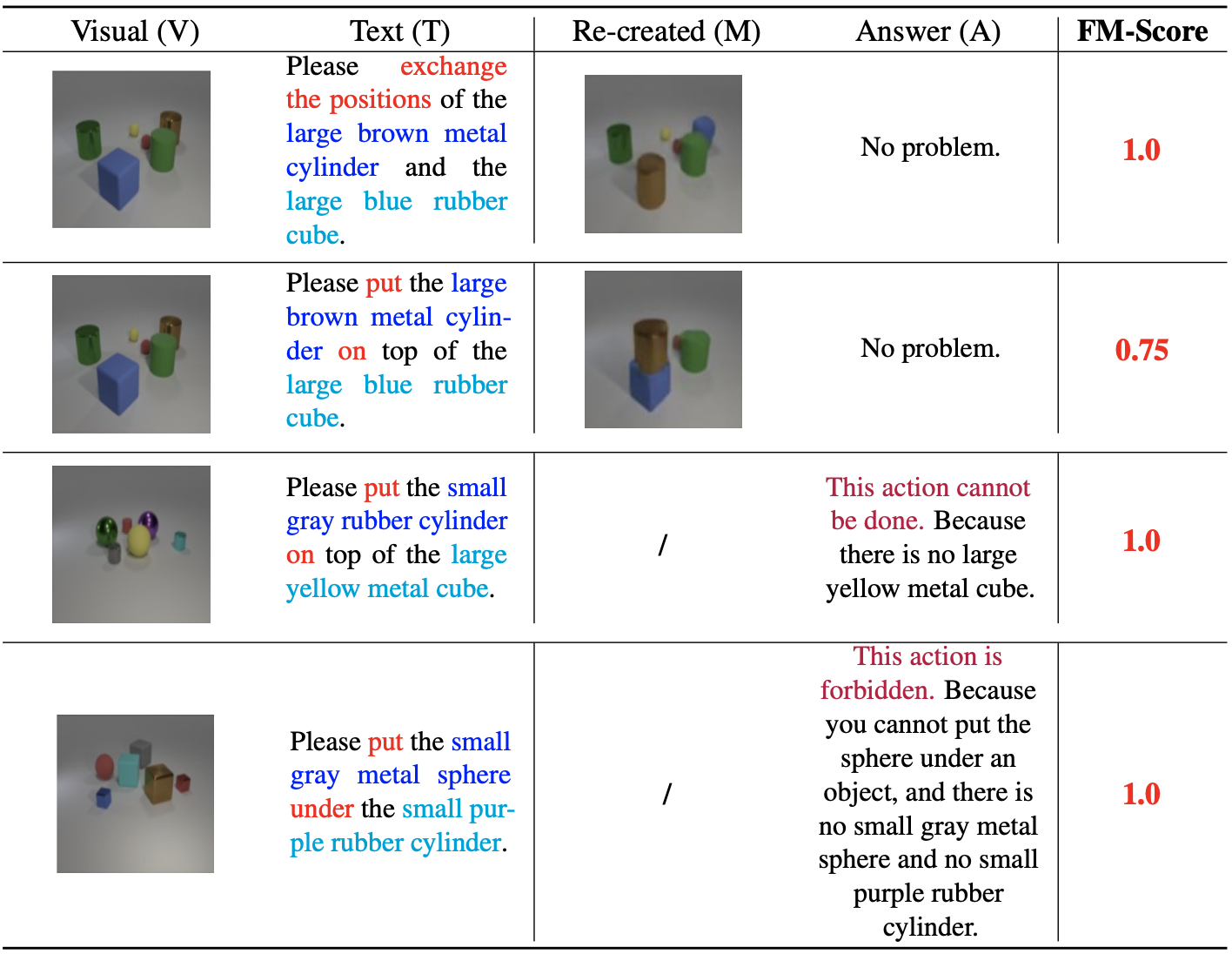
Datasets




Code and Model

BibTeX
@article{zhang2023accountable,
title={Accountable Textual-Visual Chat Learns to Reject Human Instructions in Image Re-creation},
author={Zhang, Zhiwei and Liu, Yuliang},
journal={arXiv preprint arXiv:2303.05983},
year={2023}
}